
The Flow State: When Clinical Research Finally Flows
Summary Clinical research shouldn’t feel like survival mode. The Flow State is about finding the balance between precision and ease...

Five quick ways to improve data validation
Mistakes happen in the course of data entry. A research coordinator, intending to input a weight of 80 kilograms, leaves...

OpenClinica at ACRP 2022: What to expect
OpenClinica announces the launch of its electronic health record (EHR) eSource solution, OpenClinica Unite. Unite makes it easy for research...

Clinical Data Science for Non-Data Scientists (Part 1)
What is Clinical Data Science? Einstein is often attributed to saying, “If I had an hour to save the world,...
OpenClinica Web Services Tutorial Videos
OpenClinica’s web services layer provides a powerful mechanism for programmatic data interchange between OpenClinica and other systems. Below are the...
The OpenClinica Platform – Developer Round Table Discussions
OpenClinica is a clinical trial software platform that aims to provide data capture, data management, and operations management functionality to...
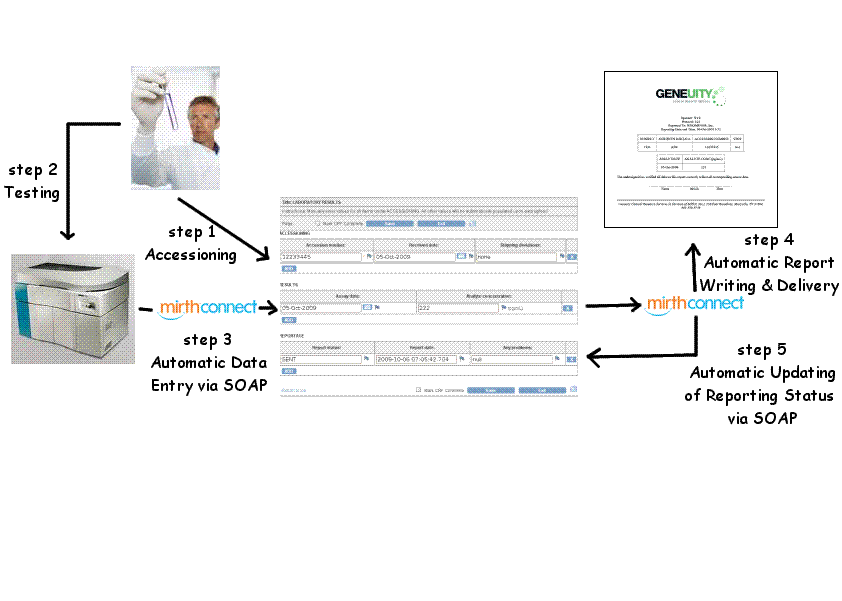
Rapid Deployment of New Functionality in OpenClinica Using MirthConnect
In a previous article, we describe how we at Geneuity Clinical Research Services exploit OpenClinica’s new web services feature to...
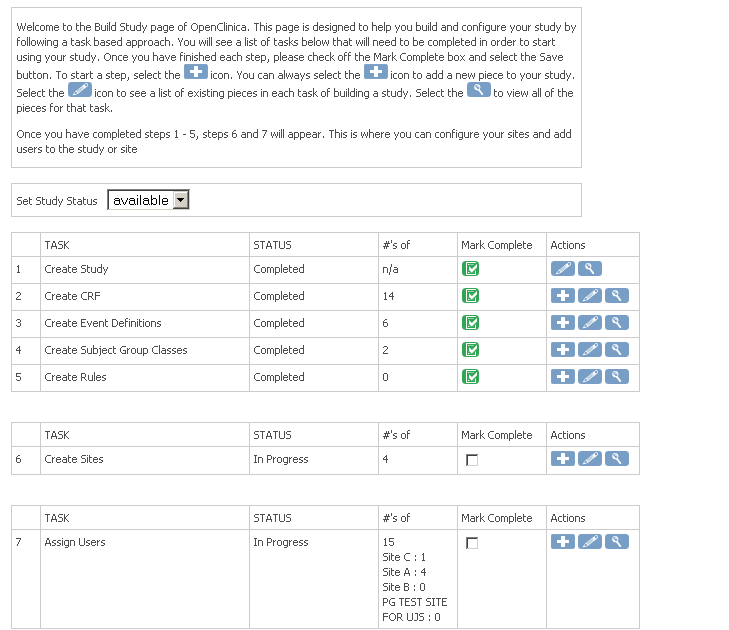
OpenClinica 3.0 Features Preview – Part II
Welcome to Part II of the OpenClinica 3.0 features! I previously wrote about three of the main features for 3.0,...
OpenClinica 3.0 Features Preview – Part I
We have been working hard on OpenClinica 3.0 for the last 9 months and are getting closer and closer to...
How a Busy Research Clinical Laboratory Deploys OpenClinica as a Laboratory Information System (LIS)
Here at Geneuity Research Services, we do laboratory tests for clients conducting clinical trials. We are a one-stop shop, handling...