HTML Tips to Enhance Your eCRF
In some cases, the display of your OpenClinica eCRF may not be exactly what you had in mind. You may...
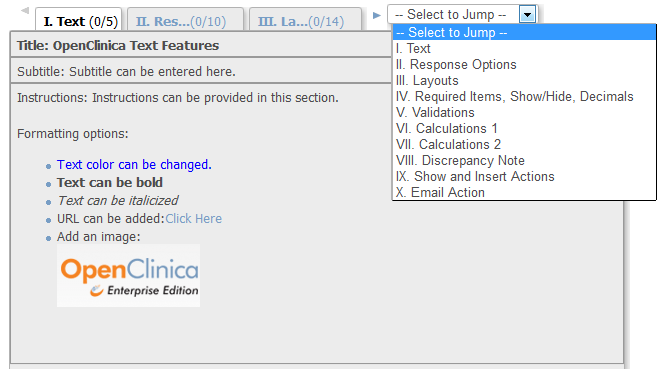
OpenClinica CRF Features – Everything But the Kitchen Sink
Whenever I teach case report form (CRF) design in the OpenClinica Central User Training class, the thought that always comes...
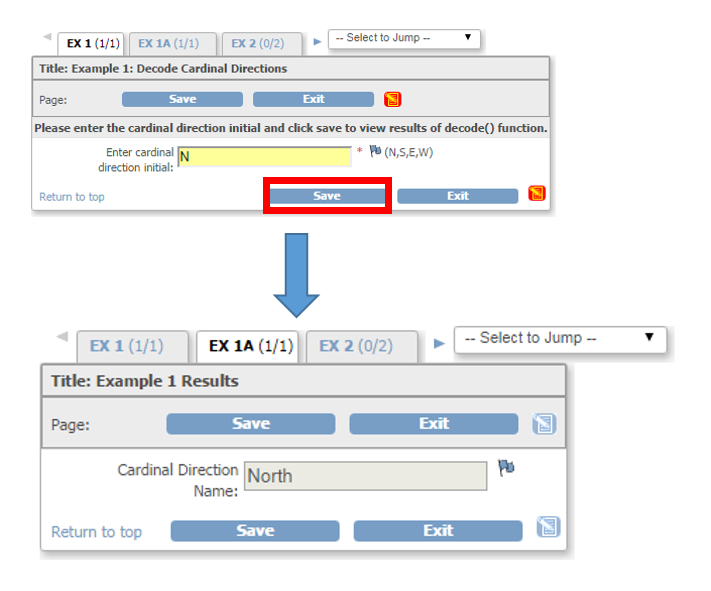
Demystifying the Decode() Function
Tips on using the decode() function to your advantage and optimizing your CRF.
Beyond Single-Selects – Managing Long Lists in OpenClinica
Here at the VU Medical Center Amsterdam, we’re implementing OpenClinica (OC) for CTMM TRACER. TRACER aims at improving diagnosis, prognosis...
The OpenClinica Platform – Developer Round Table Discussions
OpenClinica is a clinical trial software platform that aims to provide data capture, data management, and operations management functionality to...
Three Things I Learned About Export Job Performance From My Uncle Paulo
1. “Realize you can try to do it all…but you’ll do it slowly, very slowly.” It’s understandable that there may...
The Evolution of Electronic Data Capture
OpenClinica was recently featured in an article in Genetic Engineering and Biotechnology News titled “Commandeering Data with EDC Systems,” written...
OpenClinica 3.1 (project “Amethyst”) Preview
The next major milestone for OpenClinica (project code-named “Amethyst”) will be OpenClinica version 3.1. While this release contains roughly 85...

Trial Sponsors and Their Contract Labs: Better Collaboration via OpenClinica
At Geneuity Clinical Research Services, we do lab tests for trial sponsors. As readers of this blog know, we use...
Preview of the March 22nd OpenClinica Global Conference
With just a week to go, the OpenClinica Global Conference is shaping up to be an excellent event for learning...