December 4, 2015
2015 Future of Open Source Survey Results
Open source software has emerged as the driving force of technology innovation, from cloud and big data to social media...
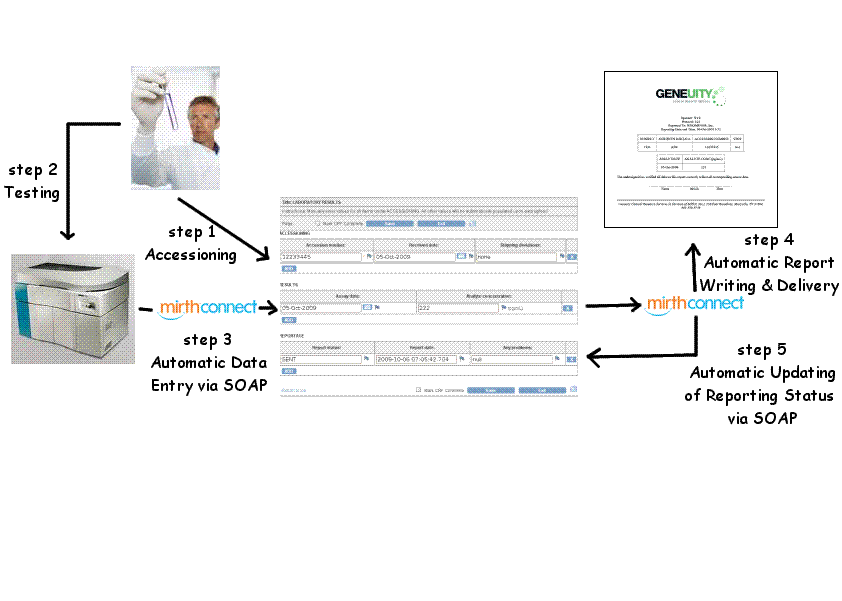
October 11, 2009
Rapid Deployment of New Functionality in OpenClinica Using MirthConnect
In a previous article, we describe how we at Geneuity Clinical Research Services exploit OpenClinica’s new web services feature to...